The highly anticipated DeepSeek AI-𝗩𝟰 was officially launched and open-sourced yesterday (24 April 2026), with two initial versions: Pro, a high-performance flagship model, and Flash, a cost-efficient version.
Back on 3rd March, I published an Advisory Brief: Seek Deeper in DeepSeek. At the time, 𝗩𝟰 was just a rumour, expected to launch before China’s Two Sessions. Experts speculated it would offer a 1M-token context, native multimodality, and a new “Engram” architecture to address catastrophic forgetting. I also argued that regulated enterprises could finally run a frontier AI on their own servers.
A major upgrade is the context length, which has been expanded from 128K to 1 million tokens. The Massachusetts Institute of Technology (MIT) licence means you can use, modify, and run it yourself. No vendor lock-in. No surprise price hikes. Just code. This directly validates the core thesis of my earlier brief: open-source AI changes the risk profile for regulated industries.
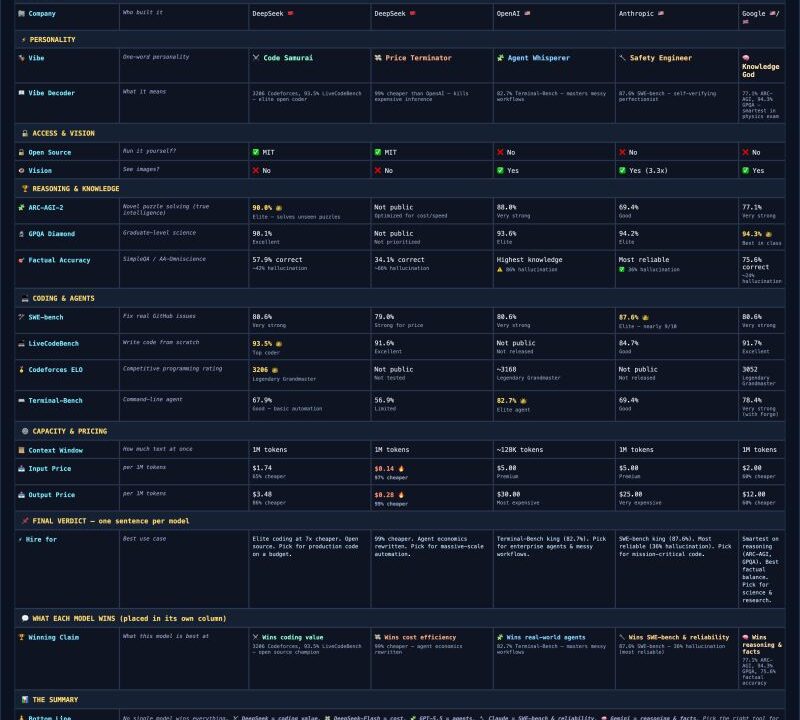
I asked DeepSeek to compare itself against other frontier models. The attached wallpaper shows the details. In short, it claims to be:
1. 𝗔 𝗖𝗼𝗱𝗲 𝗦𝗮𝗺𝘂𝗿𝗮𝗶 – according to its official benchmark report, DeepSeek V4-Pro on Hugging Face (linked in the comments) achieved a 3206 Codeforces ELO rating (on the Legendary Grandmaster scale) and 93.5% on LiveCodeBench (solving unseen coding problems from scratch).
2. 𝗔 𝗣𝗿𝗶𝗰𝗲 𝗧𝗲𝗿𝗺𝗶𝗻𝗮𝘁𝗼𝗿 – $0.28 per million output tokens on Flash. That’s 99% cheaper than OpenAI GPT-5.5 and Anthropic Claude Opus 4.7. Ideal for running millions of agent tasks without straining tight budgets.
3. 𝗔𝗻 𝗮𝗴𝗲𝗻𝘁𝗶𝗰 𝗰𝗼𝗱𝗲𝗿, not just a chatbot – 80.6% on SWE-bench. That means it fixes 4 out of 5 real bugs in actual GitHub projects. DeepSeek’s internal developers already use it daily.
It was also humbling that DeepSeek noted:
1. Google Gemini is the smartest and leads in reasoning. It scores highest on novel puzzles and graduate-level science (physics, bio, chem). If you need a genius scientist, pick Gemini.
2. Anthropic Claude excels on the SWE-bench. It fixes 87.6% of real GitHub bugs. If you need mission-critical code you can trust, pick Claude.
3. OpenAI 𝗚𝗣𝗧-𝟱.𝟱 specialises in messy real-world agents. It leads to working inside a real Linux terminal, running commands, and handling chaos. If you need an AI that actually gets things done, pick GPT-5.5.
Use the comparison picture above as a wallpaper. In my view, no single model wins everything. But if one needs elite coding power, open source, and prices that make sense, it seems worth exploring DeepSeek further. Before diving in, it would also be worth investigating Anthropic Claude and Google Gemini and comparing them with DeepSeek.
About the author
Viren Mantri is a cybersecurity advisor and former senior technology leader across Standard Chartered, UBS, McAfee, and KPMG. With 30 years of navigating the intersection of technology, risk, and regulations, he now helps organisations cut through complexity and make better security decisions.
CC-BY Viren Mantri, 2026, licensed under a Creative Commons Attribution 4.0 International License.
Disclaimer: All views expressed here are entirely mine.